
はじめに
GPU(Graphics Processing Unit)はもはやグラフィックス処理だけのものではありません。並列処理の強みを活かし、機械学習や科学技術計算、金融シミュレーションなどさまざまな分野で活用されています。今回はGPUの並列処理の仕組みや機械学習との関係、CUDAやOpenCLなどのプログラミング技術について分かりやすく簡単に基礎を解説します!
結論
並列処理とは一度に膨大な計算を並列(同時)に実行することです。
GPUは並列処理に特化した強力な演算装置のことです。
機械学習や科学技術計算など幅広い分野で活用されている。
GPUの並列処理の仕組み
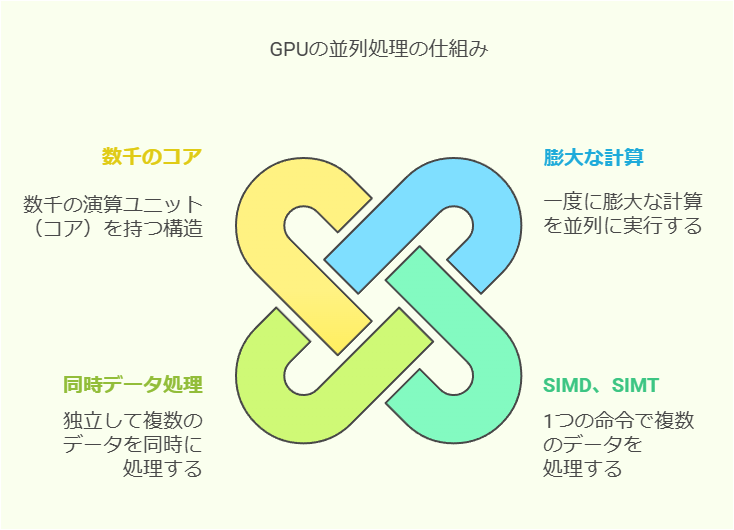
GPUは多数の演算ユニット(コア)を備えており、一度に膨大な計算を並列に実行できます。
例えば、一般的なCPUが4〜16コア程度であるのに対し、最新のGPUでは数千のコアを搭載し、それぞれが独立して一度に膨大なデータの処理を同時に実行できます。
これはSIMD(Single Instruction, Multiple Data)やSIMT(Single Instruction, Multiple Threads)というアーキテクチャによって実現されており、1つの命令で複数のデータに対して同時に同じ処理が可能となっています。
これは、以下のような用途で特に威力を発揮します。
- グラフィックス処理:ピクセル単位の描画計算を並列実行
- 科学技術計算:流体シミュレーション、分子動力学計算など
- 機械学習:ニューラルネットワークの学習と推論の高速化
GPUと機械学習の関係
AI(人工知能)に使用されている機械学習、特にディープラーニングでは大量の行列演算(並列処理)を行う必要があります。GPUはこのような計算を得意とするため、CPUよりも圧倒的に高速に処理できます。
例えば、畳み込みニューラルネットワーク(convolutional neural network:CNNまたはConvNet)やトランスフォーマーモデルでは行列の積や畳み込み演算が大量に発生します。これらの計算は以下のGPUの技術を活用することで劇的に高速化されます。
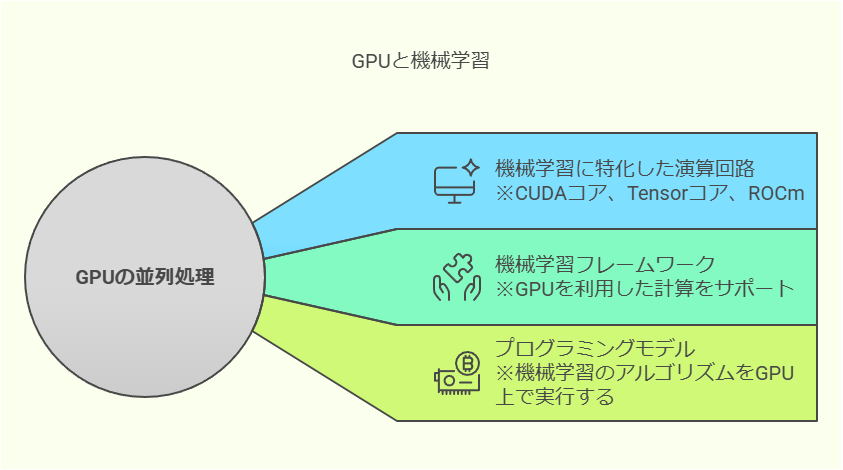
CUDAコア(NVIDIA GPU)
※NVIDIA社が開発したGPUに搭載されている演算処理装置、主に映像処理の演算が得意
Tensorコア(NVIDIA社のディープラーニング専用コア)
※NVIDIA社が開発したディープラーニングに特化した演算回路
ROCm(AMD社の機械学習向けフレームワーク)
※AMD社が開発したGPUコンピューティングプラットフォーム
また、主要な機械学習フレームワーク(TensorFlow、PyTorch、JAXなど)はGPUを利用することを前提とした設計がされており、簡単な設定で活用できます。
GPUプログラミング
GPUを活用したカスタムアプリケーションを開発する場合、CUDAやOpenCLを利用することが一般的です。
どちらのモデルも機械学習のアルゴリズムをGPU上で効率的に実行するための強力なツールです。
CUDA(Compute Unified Device Architecture)
・NVIDIA独自のGPUプログラミングフレームワーク
・C/C++をベースとし、Python(CuPyなど)との連携も可能
・機械学習・HPC(高性能計算)に最適化
OpenCL(Open Computing Language)
・ベンダーに依存しないGPU計算フレームワーク
・NVIDIA、AMD、Intel、Appleなど幅広いハードウェアに対応
・汎用性は高いが最適化にはベンダーごとのチューニングが必要
CUDAはNVIDIAの独自技術であるため、NVIDIA製GPUに限定されますが、その分パフォーマンスが最適化されています。一方、OpenCLはAMDやIntelのGPUでも動作するため、ハードウェアに依存しないコードを記述することができます。
まとめ
GPUは並列処理に特化した強力な演算装置であり、機械学習や科学技術計算など幅広い分野で活用されています。
特にGPUプログラミング言語のCUDAやOpenCLを利用することでGPUの能力を最大限に引き出すことが可能となっています!
GPUを活用することで処理の高速化や大規模データの分析が容易になり、より高度な解析を行うことができます。
今後、GPU技術が更に進化することによって、より多くの分野での活用が期待されています!
最後まで読んでいただき、ありがとうございました!

