
はじめに
近年、AI(人工知能)技術の発展により大規模言語モデル(LLM:Large Language Models)という言葉を耳にする機会が増えています。しかし「具体的にどのような仕組みなのか?」「どんな場面で活用されているのか?」と疑問に思う方も多いのではないでしょうか。
検索エンジンで質問すると、まるで人間が答えるような自然な文章が返ってくることがあります。また、チャットボットがカスタマーサポートとして対応してくれる場面も増えています。これらの背後には大規模言語モデル(LLM)の技術が活用されています!
本記事では大規模言語モデルの基本的な仕組みや具体的な活用事例、今後の課題について解説します。これを理解することでAI技術の可能性をより深く知ることができるでしょう!
それでは、さっそく大規模言語モデルとは何かについてみていきましょう。
結論
大規模言語モデルとは膨大な量のテキストデータを用いて学習された深層学習モデルのことです。
質問応答、文章の要約、翻訳、生成など様々な自然言語処理タスクを実現しています。
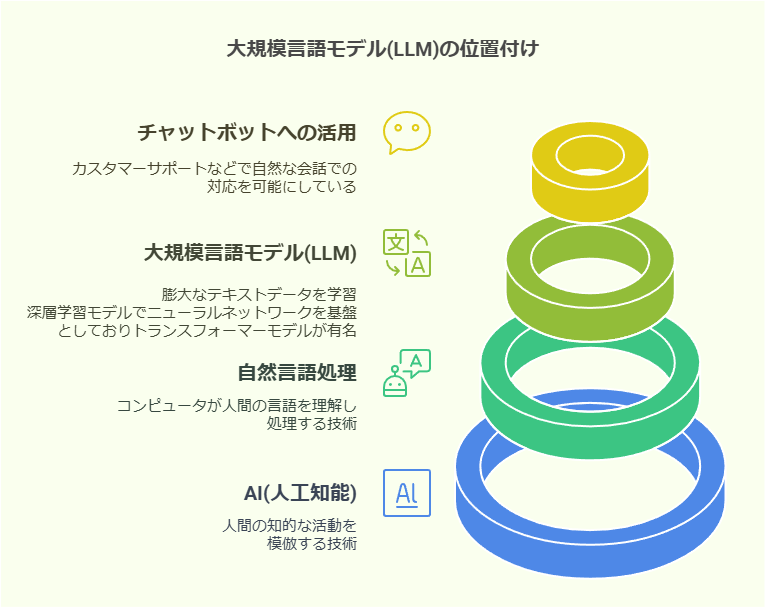
大規模言語モデル(LLM)とは?
大規模言語モデルとは、膨大なテキストデータを学習し人間のように自然な文章を生成する深層学習モデルのことでAI(人工知能)の一種です。事前に学習したデータをもとに質問への回答や文章の要約、翻訳、生成などを行います。
一般的にはニューラルネットワークの仕組みを基盤としている「トランスフォーマー:Transformer」アーキテクチャ(モデル)と呼ばれる技術が使用されており、自己注意機構などを利用して文脈を捉えることができます。
大規模言語モデルはインターネット上のテキストや書籍などを学習することで人間の言葉の使い方を理解し、高精度な文章生成を可能にしています。
次は、大規模言語モデルがどのように学習し、動作するのかについて詳しくみていきましょう。
大規模言語モデル(LLM)の仕組みとは?
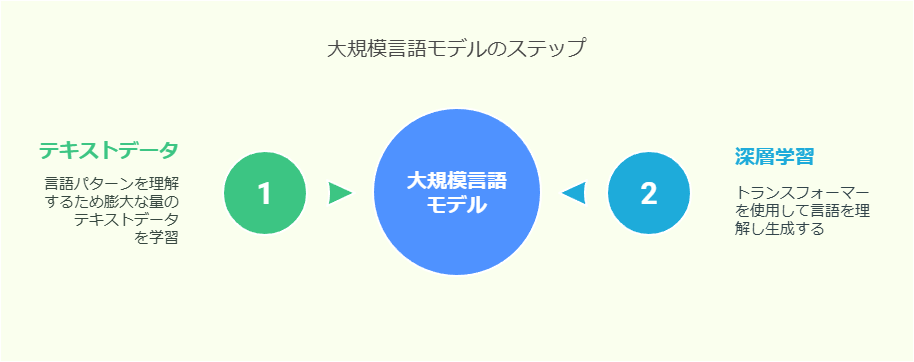
大規模言語モデルの基本的な仕組みは以下のようなステップで成り立っています。
1.大量のテキストデータによる学習
まず、大規模言語モデルはインターネット上のウェブページ、書籍、論文など膨大な量のテキストデータを学習します。この学習を通じて単語や文の出現パターン、文法、意味などを理解します。
トークン化:
テキストデータを単語や文字などの小さな単位(トークン)に分割します。
埋め込み(Embedding):
各トークンを数値のベクトルに変換します。これにより、単語の意味や文脈を数値で表現できます。
2.深層学習(ディープラーニング)の利用
次に、大規模言語モデルは人間の脳の神経回路を模倣したニューラルネットワークの基盤を基にした深層学習(ディープラーニング)を使用します。特に「トランスフォーマー」と呼ばれるアーキテクチャ(モデル)が利用されています。
主に自己注意機構などの技術を用いて、次に来る単語を予測する能力を高めます。そして、与えられた文章の文脈から次に来る単語を予測することで文章を生成します。
たとえば「今日は天気が」という入力に対し「良い」「悪い」などの単語が続く可能性が高いことをモデルが予測できます。
このような学習や予測を繰り返すことで、より自然で文脈に合った文章を生成できるようになります。
自己注意機構(Attention Mechanism)
・Transformerの核となる技術です。
・文章中の各単語が他の単語とどのような関係性を持っているかを学習する仕組みです。
・これにより文脈を深く理解し、より自然な文章生成が可能となっています。
エンコーダー・デコーダー
・Transformerはエンコーダーとデコーダーという2つの部分から構成されています。
・エンコーダーは入力された文章をコンピュータが処理しやすい形式に変換します。
・デコーダーはエンコーダーが変換した情報をもとに文章を生成します。
大規模言語モデル(LLM)の種類
代表的な大規模言語モデル(LLM)には以下のものがあります。
GPTシリーズはOpenAIが開発した大規模言語モデルです。大量のテキストデータを学習し、自然な文章生成や質問応答、翻訳など多様なタスクに対応しています。
LaMDA(ラムダ)はGoogleが開発した会話に特化した大規模言語モデルです。人間のような自然な対話を目指し、多様な話題で流暢な会話が可能です。
BERT(バート)はGoogleが開発した大規模言語モデルです。双方向の文脈理解に優れ、質問応答や文章分類など様々なタスクを高精度で実行します。Transformer技術を基盤としGoogle検索にも導入され、検索精度向上に貢献しています。
では、この技術がどのような分野で活用されているのか次の章でみていきましょう。
大規模言語モデル(LLM)の活用事例
大規模言語モデルは、さまざまな分野で活用されています。
検索エンジン・AIアシスタント
ユーザーが求める情報をより正確に提供するため、質問の意図を理解し、最適な回答や応答を可能にしています。
チャットボット
カスタマーサポートの現場では、対話型チャットボットがユーザの問い合わせに自然言語で自動対応することで顧客満足度を向上させるとともに、業務の効率化が進んでいます。
文章生成・テキスト生成
記事作成、小説執筆、詩、コピーライティングなどコンテンツ作成の自動生成に活用されています。
要約や翻訳
長文の要約生成や、自然言語で他言語に翻訳などの作業に活用されています。
プログラミング・関数
プログラミングコードやエクセル関数の生成、コードのバグ修正に利用されています。
感情分析
テキストデータから感情を抽出しポジティブやネガティブ、中立などの分析を行うことも可能にしています。
こうした技術が進化することで、私たちの生活がより便利になると考えられます。
最後に大規模言語モデルの今後の課題についてみていきましょう。
大規模言語モデル(LLM)の課題
大規模言語モデルには多くの可能性がありますが、いくつかの課題も存在します。
まず、学習データに偏り(バイアス)がある場合、不適切な情報を生成してしまうことがあります。また、事実に基づかない誤情報(ハルシネーション)の生成による信頼性の低下、プライバシー侵害の懸念なども挙げられます。さらに、悪用されるリスクや著作権侵害など倫理的な問題も指摘されています。
膨大なデータを処理するために大量の計算資源が必要となるため、環境負荷も問題視されています。
しかし、これらの課題を解決するため、新しいAI技術の開発や省エネルギー型のモデルが研究されています。今後、大規模言語モデルがどのように進化し、私たちの生活にどのような影響を与えるのか注目されています。
まとめ
本記事では大規模言語モデル(LLM)の技術やその仕組みについてお伝えしました。
大規模言語モデルとは、膨大なテキストデータを学習した、自然言語を生成することができる深層学習モデルのことでAI(人工知能)の一種です。この技術は検索エンジンやチャットボット、翻訳や文章生成など幅広い分野で活用されており、今後の発展が期待されています。
一方で、データの偏りや計算資源の問題などの課題もあり、これからの技術革新が求められています。
更なる大規模言語モデル(LLM)の進化による、より高度な自然言語処理タスクの実行の実現に期待しましょう!
最後まで読んでいただき、ありがとうございました!

